Abstract
Socratic AI is a hackathon project built over one week for the AI Scholars Principled Innovation Challenge at ASU. The premise: an AI tutor that never tells students the answer, instead detecting misconceptions in their reasoning and asking the one question that gets them thinking for themselves. Built with React 18, Supabase, and Google Gemini, it includes a real-time teacher dashboard and an optional fully local mode via Ollama. We won the $2,000 prize.
Introduction
The ASU AI Scholars’ Principled Innovation Hackathon brief asked for AI tools that were principled, not just powerful. That framing resonated with me because it put a finger on something that bothers me about most AI tutoring products: Khanmigo, Chegg, Synthesis, most of them do the same thing. Student asks question, AI explains answer (or, student pastes screenshot of quiz question, AI gives answer). It’s just a better-looking version of what students already have access to. It doesn’t close any gap, and it doesn’t necessarily teach. All the while, teachers and professors are left with low attendance in their lectures, with little clue as to whether their class is getting on with the concepts okay, or just relying on ChatGPT for their grades.
The research on this is pretty settled. Decades of work on how people actually learn, from Bloom to Vygotsky to Chi’s self-explanation effect, consistently shows that explanation received is much less effective than explanation constructed. When you figure something out through guided questioning, you retain it. When someone just tells you, you mostly don’t. This is the basis of the Socratic method. Private tutors who are good at their jobs know this intuitively. They ask, they don’t lecture. The problem is that good private tutors are expensive, and their clients are not the students who need them most.
So the concept behind Socratic AI was: what if the AI’s job was specifically not to answer? What if, instead of explaining a concept when a student gets stuck, it identified the precise flaw in their reasoning and asked the question that makes them find the answer themselves?
I worked on this with my teammates Akshaya Nadathur and Pranjal Padakannaya. It’s our second hackathon win together, which still feels a little unreal to say.
The Idea
The original concept in my notes was more ambitious than what we finally built (When isn’t this the case though). We had sketched out plans for a full misconception graph: an interactive, directed graph of known wrong mental models students commonly hold in a given domain, grounded in education research (see Concept inventory - Wikipedia), with validated questioning sequences for each node. The idea was that the AI wouldn’t be improvising a tutoring strategy, it would be executing a research-validated one, just generating the natural language at runtime.
What we actually shipped is closer to: a carefully constrained LLM with a system prompt that forces Socratic behavior. The model is instructed to always respond with one of three tags: [SOCRATIC], [HINT], or [DIRECT]. Socratic is the default, a question that gets the student thinking. Hint gives a nudge without resolving the uncertainty. Direct is reserved for when a student has genuinely struggled and needs a lifeline, controlled by an attempt threshold the teacher can configure → after all, it’d be counter-productive to have students drop use of the tool entirely because it keeps quizzing them on something they just aren’t able to figure out.
This is simpler than a misconception graph and I think it actually works better in practice for a hackathon scope, at least. The LLM is good at detecting when reasoning is wrong. The tagging system just forces it to respond in a way that uses that detection without short-circuiting the student’s thinking process. The behavior you get is recognizably Socratic, even if the underlying mechanism is less elegant than pre-built research-validated sequences.
One thing I noted in the original design document and thought was worth calling out explicitly: the obvious failure mode is frustrating struggling students. If the AI never gives an answer, students who are already behind might disengage entirely. Naming that tension explicitly in our pitch, and showing the hint threshold as our design response to it, was something the judges seemed to respond well to.
Building It
The hackathon ran from February 20 to 27. A week is quite a bit longer than a typical 24- or 48-hour format, but as most things go with CS students, there was a lot of procrastination (and genuine scheduling conflicts) that made the bulk of our development run over three days, Feb 23-26.
Day one (Feb 23) was scaffolding and design. Pranjal put together the initial HTML wireframe POC demonstrating the core concept. I scaffolded the React app, designed the initial theme, and built all the components with CSS Modules. Meanwhile Akshaya helped find all the important research about the underlying principles, which we’d need for our system prompt and tone tuning. The first design looked striking but felt wrong for an educational context once we started using it. Something about asking students to do stressful academic work inside a dark moody interface → probably because it was vibe-coded with Claude as a simple POC to get our bearings, lol.
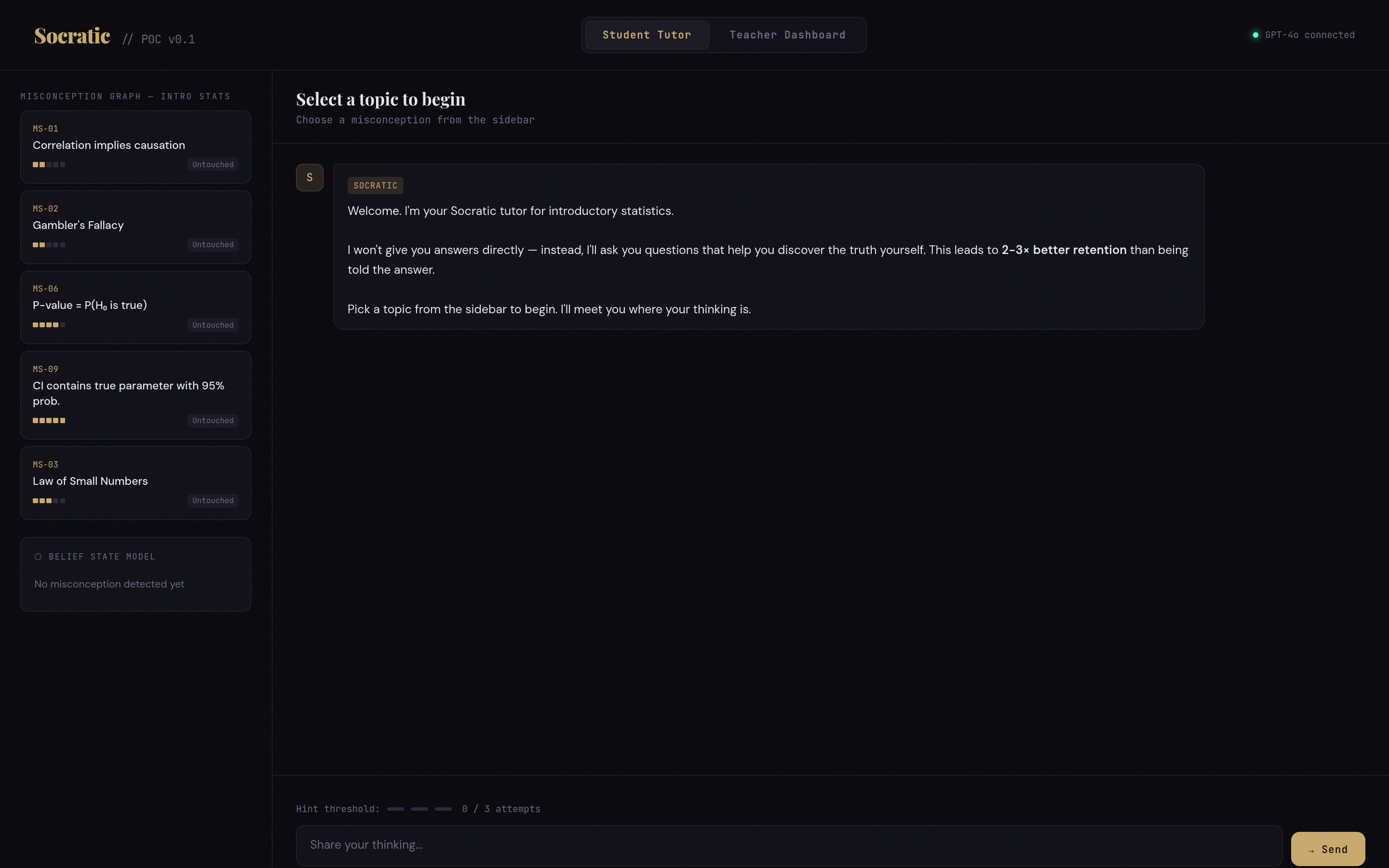
Day two (Feb 25) was the backend. We stood up a Supabase project with a seven-table PostgreSQL schema, implemented role-based auth (email/password with access-code-gated signup, where the code determines whether you’re a student or teacher), and deployed the first two Deno edge functions: socratic-chat, which builds the system prompt and handles the LLM dialogue, and end-session, which finalizes sessions and persists concept scores. Akshaya and Pranjal built the teacher dashboard: five tabs (student progress, lessons, misconceptions, concept beliefs, access codes), wired to Supabase Realtime so the teacher sees students’ results as they come in.
We also rethemed. The final design is warmer: off-white background, green accent for progress, orange for attention states, Nunito for display, DM Mono for code. It feels more like a classroom tool and less like a terminal. (Loosely inspired by Duolingo)
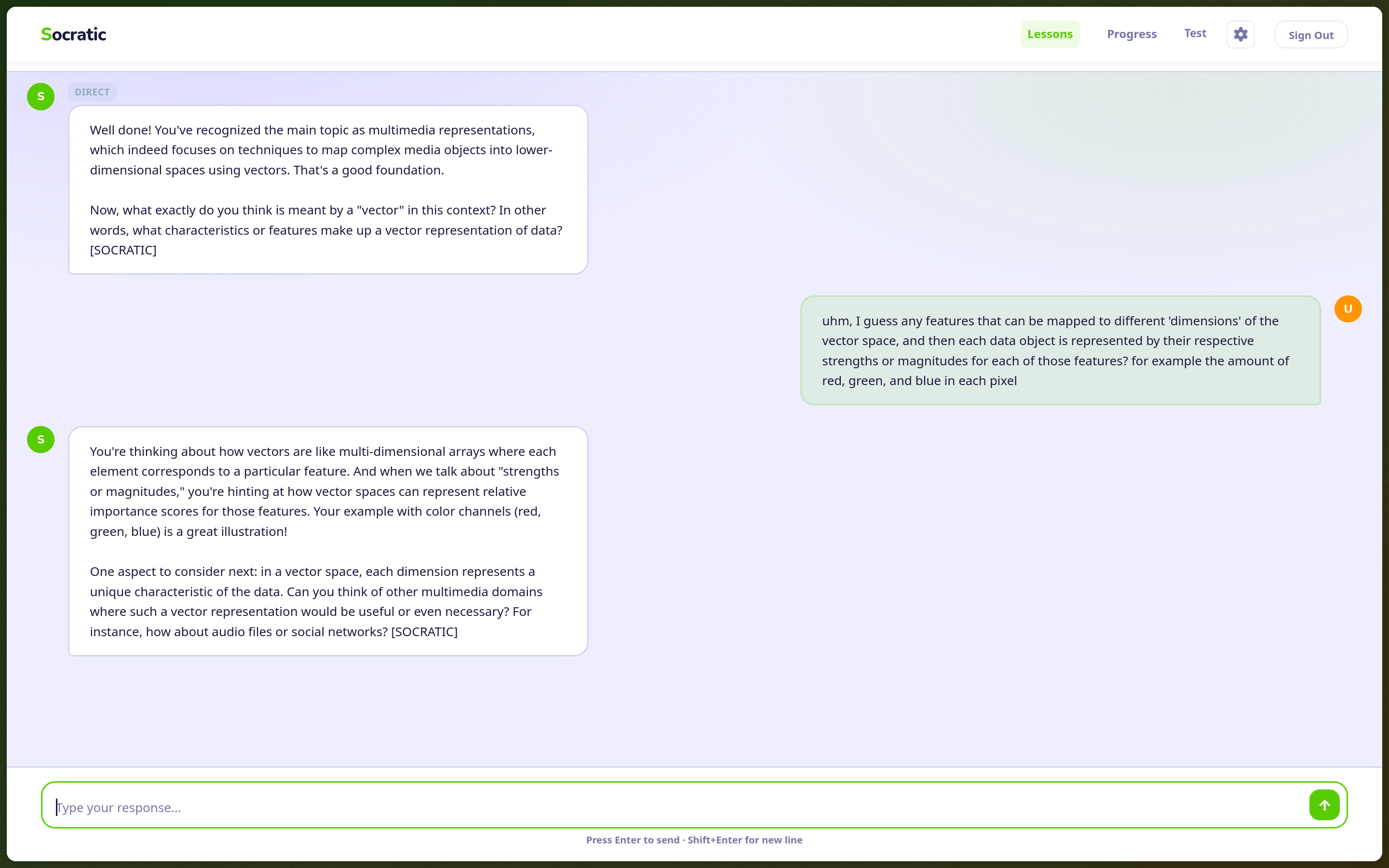
Day three (Feb 26) was the longest. This was where we added local LLM support via Ollama, built a post-session recap page, a student progress dashboard, client-side PDF text extraction, and a handful of teacher-facing features. This is where the product really went from a simple ‘ChatGPT Wrapper’-adjacent tool, to a fully fledged app, a product of its own.
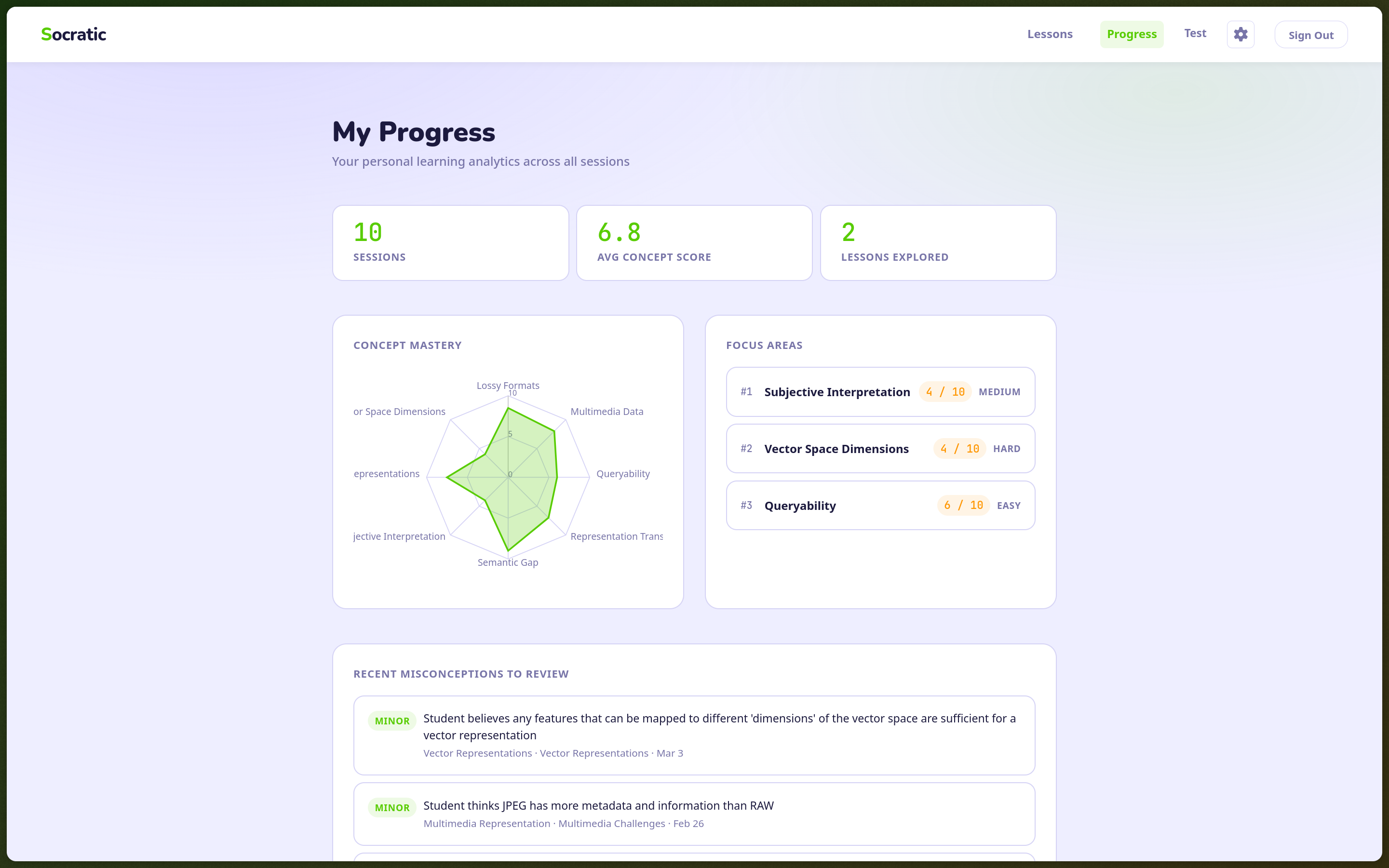
The Local Mode
One of the things I’m most satisfied with in this project is the local-first option. Students can toggle between “Cloud” (conversations go to Gemini via edge functions) and “Local” (everything runs on-device via Ollama). In local mode, no conversation data ever leaves the browser. The chat calls localhost:11434 directly. Concept extraction happens in localAnalysis.ts. Only the final summary scores and misconception labels get written to Supabase, not the raw dialogue.
This matters for the equity pitch. If you’re targeting under-resourced schools and underserved communities, you can’t assume those schools are comfortable sending all student conversation data to a cloud AI. Some won’t be. Some can’t be, legally. Having an on-device option with explicit privacy disclosure addresses that concern without making the product less capable for institutions that don’t have it. Moreover, we didn’t want to build another Cloud-based model wrapper that would illicit the building of more AI data centers down the line, we’ve seen enough about the destruction and harm that those cause.
The data notice in the settings panel says it plainly: “Cloud: your conversation is sent to Gemini for analysis when you end a session. Local: your conversation stays on your device. Only summary scores are saved.” The choice is visible and the tradeoffs are named.
Getting the local path to produce the same behavior as the cloud path required building systemPrompt.ts, a pure TypeScript function that mirrors the socratic-chat edge function’s system prompt construction character-for-character. Ollama with the local model gets identical instructions to Gemini. The response format is the same. The tag parsing is the same. It wasn’t glamorous work but it meant the Socratic behavior didn’t degrade when you switched providers.
The Teacher Dashboard
I think the teacher dashboard is what made the pitch land. Most AI tutoring tools treat the teacher as someone to route around. The implicit message is: the AI can do it better, so we’ll just sidestep the instructor. Our pitch was the opposite.
Teachers see, in real time, which concepts students are struggling with and which misconceptions are forming. Not “30% of students got question 4 wrong”, but specific wrong beliefs, categorized and tracked per student. The dashboard pulls from Supabase Realtime, so as sessions complete, the teacher’s view updates live. They can filter by student, by lesson, by concept. They can see which misconceptions are shared across the class and which are isolated.
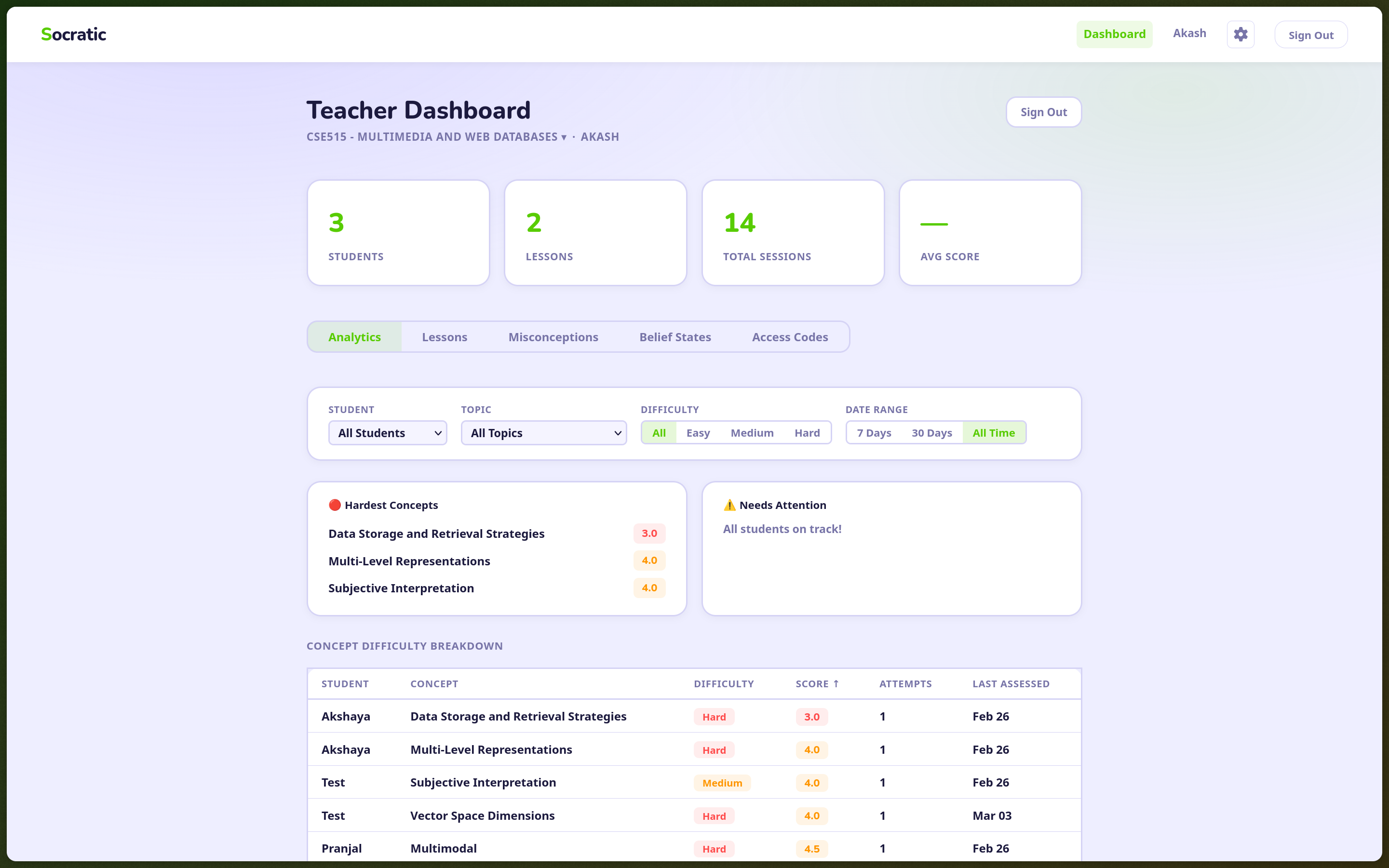
The point is that one teacher with 35 students can now intervene precisely, on the specific conceptual gap that’s affecting most of the room, rather than reteaching everything or guessing what to revisit. That’s a meaningful change in what a single human teacher can accomplish. And it keeps them fully in the loop rather than treating them as a stakeholder to be minimized. We’re not racing to build the next AI product that will replace human workers and boost shareholder value, principled innovation was firmly our sole objective, and we believe we found a balance to achieve just that.
Winning
Winning still caught me off guard a bit, mostly because the core of the pitch was a principled argument against a pattern that most AI products currently use. It’s a harder sell than “look what AI can do.” You’re essentially saying: here’s a thing AI could do that we’ve deliberately chosen not to let it do, and that constraint is the product.
There were also a dozen other teams, each with their own amazing, innovative, and impressive products and pitches. The competition was seriously fierce, and that was great to see considering a good number of the participants weren’t seasoned users or builders of AI, some weren’t even Comp. Sci. majors!
Nevertheless, team HackerBeans, as we playfully call ourselves, prevailed, and won the $2000 scholarship as a reward. It was a great experience with a lot of learning and fun, and I hope it won’t be our last win as a team either.

Takeaways
Building something genuine matters more than the internet and economy give it credit for. In a world of infinite growth, unregulated and reckless expansion of AI and the permissions we grant it, and an overwhelming sense of fear of being replaced by it, we want to remind the world that there’s good to be done with this technology, and that’s the kind of innovation all bright minds should be focusing on.
If you’d like to reach out to me or any of my teammates regarding our work and/or future projects, all three of us are currently looking for Summer 2026 Internships and would love to hear from you! I’ve put all our LinkedIns below:
References
- Chi, M.T.H., De Leeuw, N., Chiu, M.H., & LaVancher, C. (1994). Eliciting self-explanations improves understanding. Cognitive Science, 18(3), 439-477
- Bloom, B.S. (1984). The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring. Educational Researcher, 13(6), 4-16.